floverfelt.org

Thoughts, notes, etc.
What are Ben Shapiro & Pod Save America Talking About? An NLP Analysis
by Florian
I love podcasts. I’m subscribed to about 20 right now and I download a few more each week, usually.
I used to listen to a lot more partisan political podcasts, which I’ve cut back on for my own sanity. Two of the regulars I listened to back then were The Ben Shapiro Show and Pod Save America (PSA). I don’t particularly like either of these podcasts but they do provide a good news balance between the left and the right and their respective hosts are decent enough, interesting people.
Likewise, I’ve always been curious about Natural Language Processing (NLP) and some of its applications. I find it to be a nice blend between computer science and the liberal arts.
I saw this as a good opportunity for a project - download 50 of the latest Ben Shapiro Show podcasts and 50 of the latest Pod Save America podcasts, transcribe them into text, and run some analyses on them. Let’s see what we can find out…
Audio Data Collection
Like most data science projects I’ve done, the data collection took the longest amount of time by far.
Podcasts are pretty easy to get ahold of since they have publicly available RSS feeds. It was just a matter of downloading them.
I did that all here.
I knew my audio recognizer required wav format, so I went ahead and converted them in-place to .wav for usage later. I do wish I had named them with the timestamps in the filename. I feel like that would make it more robust for later analysis and file sorting. It would also be good to add some error handling/recovery mechanism. Like if the downloaded file already exists, continue. Oh, well, next time!
I initially wanted a larger set of podcasts - 100 from each instead of 50 - but I’m really glad I didn’t. The audio transcribing (which I’ll get to in the next section) took a long time as it was.
Transcribing the Audio
This is where things went off the rails a bit. Google and AWS both offer their own transcription service, but it’s surprisingly pricey.
At that amount, I’d be paying ~ $1.40 per podcast, which would cost me $140 for this little side project. I didn’t really want to spend that much, so I opted instead to use pocketsphinx.
Pocketsphinx Observations
Pocketsphinx is a free library provided by CMU to transcribe speech or audio into text. It’s a pretty robust project and it worked fine for what I was trying to do, though I have a few caveats if you’re planning on using it.
First, it really only works well on snippets of audio. If you try to transcribe an entire 30 - 40 minutes in one go, it’s going to mangle it and mangle it badly. I found 10 - 60 second chunks of audio to be ideal. I had to add this chunking step into my processing of the source audio.
Second, it’s slow. It took about ~ 48 hours to go through all 100 podcasts. That’s not exact, as it would fail occasionally and I’d have to restart it, but it took roughly that amount of time to process, which is about half of the realtime amount of time it would take to listen to all of them.
Finally, it’s not great at transcribing podcasts. I can’t speak to how it works with cleaner audio, but podcasts it struggled mightily with. I think the overlapping voices, music, and just generally “things besides speech” in the source really threw it off, especially in Pod Save America which has multiple hosts speaking at once, laughing, etc.
As an example, here’s the first few lines of the first Pod Save America:
the bread and butter pods in america is unstable her rehiring jeez i'm helpless firing yes was the
preferred to help you find qualified candidates fast and that you can try for freedom of her dot com
slash courted separate it'll be fine great people for just about every job in nearly every industry with
you need to hire in acupuncture
...
is tromp first america locks and so he's thinking about ways in which he did hope and self about ways
which featured hall saw the props for the karcher regardless of top of water helps or hurts him
politically and we did the policies that he offered just this became massive ignorance to what's
happening in america and it's not surprising that is hehas been watching fox news air and fox news would
make you think that this is all could impeachment hoax
It produces this weird word salad that you can glean the general gist of what’s happening with.
Compare that with the first few lines of Ben Shapiro:
new york governor andrew cuomo is takes responsibility for new york's disaster as mere build body of
slams the jewish community immediate sweetness second look and hillary clinton gore says joe biden and
shapiro says the bench russia man to beat them shapiro show is sponsored by express it began your arm
when at the should not be public protectors of the express began at com slash panel will come for one
thousand that disability was special about this exercise
It’s just accurate enough to get what’s happening - you can see the intro leading to the ad copy - but reading it as a transcript is unintelligible.
I was hoping the sheer volume of data I was putting into the NLP analysis of these would outweigh the errors made by pocketsphinx - an assumption which turned out to be true.
I’m no expert with pocketsphinx by any means, I’m sure there’s ways to speed it up and make it’s transcription more accurate. As a future project, it would be cool to use Google and AWS transcription (which had perfect accuracy on the snippets I tested by the way) to transcribe 10 - 20 podcasts. Then use those highly accurate transcriptions to train pocketsphinx on and then transcribe new podcasts with it. But that’s for another time. As it was, pocketsphinx worked great for this little project.
Text Analysis
I assembled all the transcribed podcasts into a single corpus each for Pod Save America and Ben Shapiro’s Show.
I was going to do more in parse.py but I decided to switch over to using jupyter notebooks for the rest of the analysis once I had the corpus assembled.
I then removed the stopwords, tokenized the data, etc. from each podcast corpus and then ran through some exercises out of the nltk book.
Despite the transcription issues in pocketsphinx, I feel like this was all around a success.
Inherent Biases
To start, let’s look at the collocations of the two corpuses:
ben_text.collocations():
united states; com slash; dot com; new york; joe biden; white house;
federal government; stay home; health care; andrew cuomo; back work;
south korea; social distancing; bernie sanders; one second; little
bit; public health; dont know; two thousand; second first
psa_text.collocations():
joe biden; dot com; donald trump; bernie sanders; com slash; health
care; south carolina; two thousand; new hampshire; super tuesday;
white house; mitch mcconnell; dont know; democratic party; twenty
twenty; make sure; little bit; last night; new york; every single
Pocketsphinx and nltk did a great job here. These are accurate pairings and indicate a general success of the transcriptions despite the errors we saw above.
Before we proceed any further, though, we have to consider something big here:
The Ben Shapiro Show is producing a metric f%#@ ton of content. It publishes Monday - Saturday and as such, we saw about the last 8 weeks of news with Ben Shapiro.
Pod Save America, on the other hand, is biweekly, which means we’re looking at the last 25 or so weeks of news. These aren’t really apples-to-apples comparisons time wise.
You can actually see this in the collocations, notice how Ben’s is focused on more recent news surrounding the coronavirus - Andrew Cuomo, getting back to work, South Korea, etc.
Whereas Pod Save America is focusing on more of the big picture items of the last several months - Joe Biden, the primaries, the election, etc.
This skews a lot of the results and should be kept in mind. Anyway, let’s play with the data a bit.
Donald Trump
The big man in the room for both of these podcasts.
print('Ben Trump mentions: ' + str(ben_fdist['trump']))
print('PSA Trump mentions: ' + str(psa_fdist['trump']))
---
Ben Trump mentions: 100
PSA Trump mentions: 407
Unsurprisingly perhaps, Pod Save America talks about Trump a lot. It gets even worse (better?) once you realize that the transcription often misspelled “trump” as “tromp”:
print(ben_fdist['tromp'])
print(psa_fdist['tromp'])
---
24
359
That means Pod Save America mentions the Donald about fifteen times an episode, which looks like this:
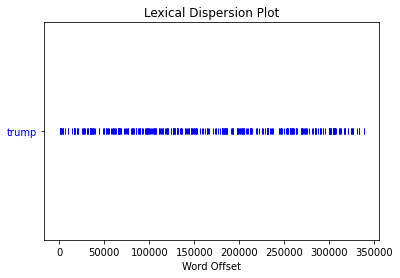
Compared to Ben:

Again, this may be fairly skewed due to the format. Or it could be that Ben, as a conservative who I think disapproves of the president’s behavior, is trying to stay silent on Trump and focus on the opposition.
Joe Biden
How does a liberal, progressive podcast compare in its treatment of Biden to Shapiro?
Let’s see:
print(psa_text.similar('biden'))
---
know talk like one people think also still want way needed look ive
directly help job need mbeki time spoke
print(ben_text.similar('biden'))
---
rights man books acted might dealt rapist platform campaign exotic
plumbers ely
A bit of word salad here, but you can definitely pick up on the difference in sentiment. If I had to guess, I would say Ben has been talking a lot about the Tara Reade allegations.
Coronavirus
This is pretty cool, you can watch as the coronavirus news is picked up by Pod Save America. Remember, reading this left to right is reading the most recent to oldest:

I don’t want to bore people with too many of these, but it is cool to see the different insights you can draw with just these basic queries and plotting.
2020 Contenders
How much did PSA mention the top 2020 contenders for the democratic primary?
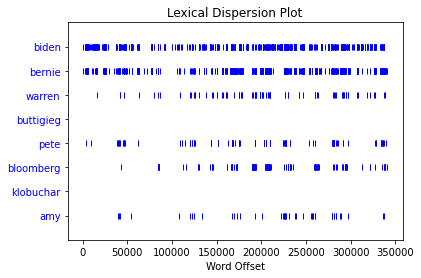
Kinda neat stuff. I didn’t feel like it was worth it to do with Ben’s show as it’s daily. We get a larger scope of time with PSA.
NLP & the Podcast Advertising Model
I have to assume that advertisers are integrating NLP into their ad recommendations/costs for ad placement on shows. If not, this is a huge missed opportunity.
Rather than relying on user inputted tags, reviews, etc. to recommend podcasts, you could transcribe them, perform text and sentiment analysis on them, and then recommend based on that data or on similarity to other transcribed podcasts.
For a fully fledged software team, I feel like this would not be super difficult. You’d have to exclude a lot more stop words than I do here and do some machine learning to identify and classify podcasts into genres, sentiments, along with user preference.
Final Thoughts
I hope people find this interesting and as a good jumping off point as to the things that can be done with basic NLP analyses. I may revisit this topic in the future with other podcasts.
In particular, I feel like Joe Rogan’s podcast would work exceptionally well with NLP. It’s structured to only have one person talking at a time, the quality is high, and there’s a lot of content to pull from.
If you have suggestions, please reach out and let me know.
- Florian
tags: podcasts - nlp - python - blog - posts